Impala架构介绍¶
Impala要解决的问题¶
我们都知道MapReduce在Google内部应用很广,社区有对应的MapReduce实现Hadoop。 但是Hadoop的MapReduce框架本身重点考虑高容量并发,具有很强的扩展能力和容错能力,但对任务的低延时考虑较少. 比如:
- TaskTracker新启动一个Task时需要启动新的JVM;
- Reduce必须等待所有的Map执行完成之后才开始执行其运算逻辑;
- Reduce通过轮询方式获知MapTask的完成情况,需要主动拉取Map的结果,而Map的结果需要写到本地磁盘;
- ...
因此,Hadoop的MapReduce是一个批处理的系统,并不适合实时处理。
针对实时Adhoc查询,Google内部有Dremel,之所以Dremel能在大数据上实现交互性的响应速度,主要使用了两方面的技术:
- 对嵌套结构的嵌套关系型数据采用了全新的列式存储格式;
- 分布式可扩展统计算法,能够在几千台机器上并行计算查询结果。
google的Dremel不支持Join,而其Tenzing支持join,但是基于MapReduce,性能相对逊色。 由于Impala的架构师Marcel Kornacker从Google出来 [1] ,Impala的设计有可能反映了Google内部对Dremel和Tenzing的改进思想.
也因此,Impala不会完全替代Hive,Impala是Hive的一个补充,可以快速的响应一些简单的查询请求。
Impala总体介绍¶
Impala是Cloudera开发并开放代码的一个MPP模型的实时海量数据的分布式查询引擎 (当前最新版本1.1). 该查询引擎主要针对“低延时的实时数据查询与分析”应用,支持直接访问HDFS(hive)和HBase中的数据。
Impala采用了和Hive相同的类SQL接口,但并没有采用MapRed框架执行任务,而是采用了类似Dremel的方式, 其实Impala就是自己实现了一个执行引擎。 这个引擎不像MapRed一样是一个通用框架,并且也没 有任何failover和high availability的设计.
Impala的特点:¶
Cloudera官方博客 上列举了:
- Thanks to local processing on data nodes, network bottlenecks are avoided.
- A single, open, and unified metadata store can be utilized.
- Costly data format conversion is unnecessary and thus no overhead is incurred.
- All data is immediately query-able, with no delays for ETL.
- All hardware is utilized for Impala queries as well as for MapReduce.
- Only a single machine pool is needed to scale.
另外,补充一些:
- 面向实时查询,结果秒级返回
- 兼容hive的类sql语法,但暂时不支持udf和嵌套结构;
- Impala采用与Hive相同的元数据、SQL语法、ODBC驱动程序和用户接口(Hue Beeswax),这样在使用CDH产品时,批处理和实时查询的平台是统一的
- 支持从hdfs和hbase读取数据
- 编译前端采用Java实现,而运行时用c++实现,并利用了llvm的技术,动态优化执行代码;
- 没有任何failover的设计,也没有对慢节点进行考虑;
- Impala与Dremel相比,支持join,而且支持不同类型的文件格式;
由于在分布式环境中,机器宕机是一种常态,如果一个大任务在执行过程中发生机器故障,重算整个JOB开销很大。 而Impala的设计理念就是,执行速度足够快,快到如果失败了,重新执行一遍的代价也不大。 也因此,Impala无法取代Hive,而且Impala扩展能力不如MapReduce框架。 当前只能**部署300台**左右,机器数目继续增加,慢节点和机器故障带来的问题就会比较突出,影响性能表现。
Impala总体架构¶
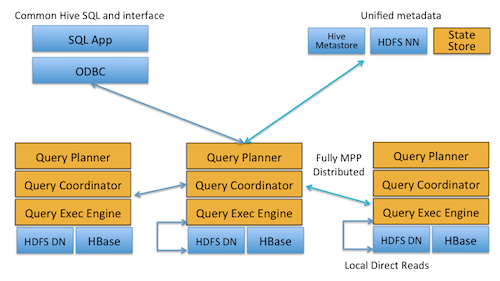
一个SQL执行过程如下:
- client通过thrift接口连接到某个impalad,然后调用query(sql)接口提交Query;
- Impalad接收请求:
- 新建QueryExecState(它包含这个Query执行的上下文信息, 成员包含coordinator等).
- 通过JNI或者Thrift接口(如果使用PlanService),完成Plan的编译;
- 调用QueryExecState的Exec, 新建coordinator, 开始执行Query;
- 返回query handle;客户端调用返回;
- Client得到Query Handle后,调用get_state轮询Query的状态; 当impalad的Coordinator获取到第一个RowBatch之后将状态设置为SUCCESS.
- Client一旦发现query的状态是Success之后将调用Fetch接口获取数据;
StateStore/Impalad¶
在一个运行中的Impala系统中,主要包含两类服务进程:
- statestored 这是一个中心进程,它的主要功能就是维护(impalad)进程的信息。设计应该是支持Query的调度的,不过暂时还不支持;
- impalad 这是一组进程,它们会与数据节点所在的机器混部, 对外提供查询服务. 每个impalad进程同时充当两类角色:查询的主控者 (coordinator) 或者查询的分布式工作单元 (backend). 当客户端发起一个SQL查询时,首先通过thrift连接到任意一个impalad上. 该Impalad负责与client交互,该impalad在执行查询中,将可以分布式执行的计算分发到其他impalad上执行。 此时其他impalad充当工作单元的角色。
交互流程:
- StateStore: 它通过创建多个线程来处理Impalad的注册订阅(Callback). 处理订阅信息是通过thrift接口,提交client请求给相应的Impalad处理;
- Impalad: 在启动时会向StateStore注册StateStoreSubscribe,如果注册不上,会反复注册,直到注册成功后才能提供服务; 为了防止StateStore在挂掉后不致于完全不能工作,Impalad会缓存一份当前可用的impalad列表, 虽然这有可能导致执行计划分配给实际不可用的impalad导致Query执行失败.
目前StateStore还不提供对元数据的更新订阅,因此impalad的Meta缓存可能不是最新,必要时需要reflush下。 而且,目前来看StateStore的这些功能可以完全使用ZK来替代(需要statestore支持Query级的调度)
模块之间的RPC调用¶
- Impalad/Impala Service: Client(默认提供impala-shell实现)调用Thrift接口来完成提交Query,查询结果等. * Impalad beeswax,提供beeswax接口,默认端口号21000 * Impalad HiveServer2,提供HiveServer2接口,默认端口号21050
- Impalad/Web Serveice: 默认端口25000 提供http服务,可查看impalad当前正在执行的query进度,Profile日志分析,Cancel Query等,方便开发调试;
- Impalad/Backend Service: impalad之间通信的内部thrift服务。默认端口22000
- Impalad/StateStore Subscriber Service: 和StateStore交互的service接口,默认端口23000
- StateStore/StateStore Web Service: 默认端口25010 查看StateStore的状态等
- StateStore/StateStore Service: 默认端口24000, 提供Impalad注册StateStoreSubscribe.
Impala的主要代码¶
Impala的主要代码包含在三个目录中:
- common/thrift:包含了thrift接口与数据类型定义。在Impala中,thrift是通用的数据交换格式,包括进程间通信、Java和C之间的数据交换。
- fe:包含Impala的编译部分:词法分析、语法分析、语义分析、执行计划生成。
- be:包含Impala的服务进程与运行时系统。